
마케터의 네이버 급상승 검색어 크롤링 해보기(V2)
Naver 급상승 검색어 크롤링(DataLab)
이전에 포스팅된 글(마케터의 네이버 급상승 검색어 크롤링 해보기)에서는 Python의 BeautifulSoup만을 활용하여 네이버 메인의 급상승 검색어를 크롤링하는 방법을 소개하였는데, 현재 그 방법은 BeautifulSoup가 네이버의 전체적인 코드를 가져오지 못하게 되면서 사용할 수 없게 되었습니다.
그래서 단순 BeautifulSoup만이 아닌 Selenium을 함께 활용하여 네이버 급상승 검색어를 크롤링 해보는 방법을 소개해 보려 합니다. 기존에는 네이버 메인에서 데이터를 가져왔다면, 새로운 방법은 조금 더 다양한 정보를 접할 수 있는 네이버의 DataLab에서 급상승 검색어를 크롤링 했습니다.
(이후에 DataLab에서 다양한 것들을 시도해 볼 예정입니다…)
Naver DataLab
우선 Naver DataLab은 네이버 메인의 급상승 검색어 정보를 확인할 때, 우측 하단의 버튼을 통해서 접속이 가능합니다.
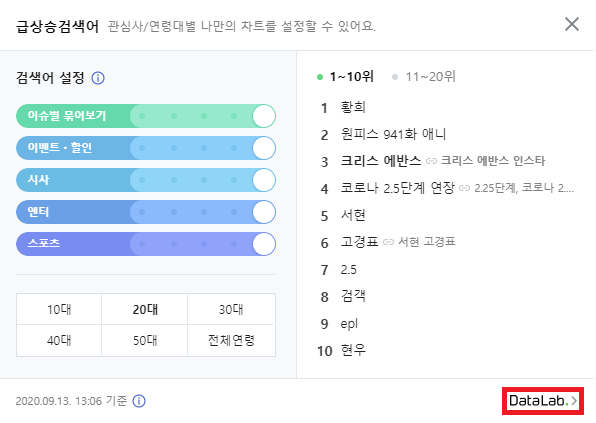
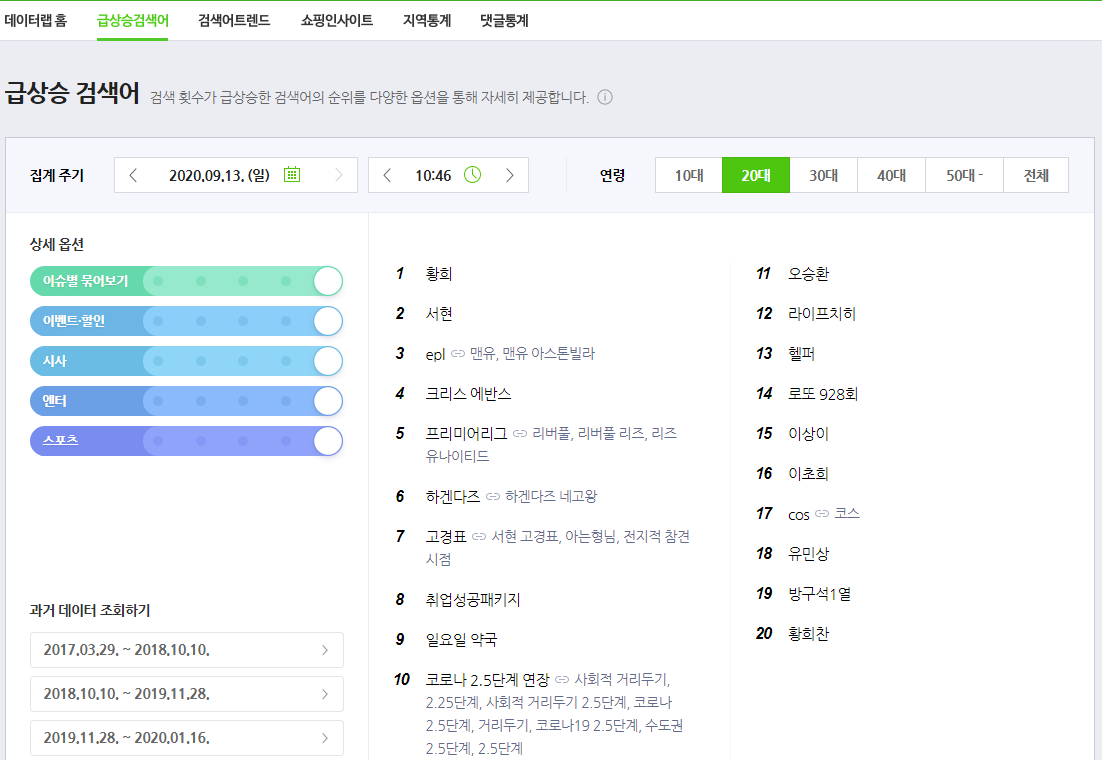
접속을 하게 되면 날짜 와 시간 및 여러가지 상세 옵션에 따른 급상승 검색어를 확인할 수 있는데, 이 페이지에서 1위부터 20위까지의 급상승 검색어를 크롤링하는 프로그램을 만들었습니다.
네이버 급상승 검색어 크롤링 프로그램 : Naver_Keyword_Crawling_DataLab.exe
크롤링 프로그램은 위 링크를 통하여 다운 가능하시지만, 해당 프로그램을 정상적으로 작동시키기 위해서는 우선 크롬 드라이버 프로그램이 필요합니다. (Selenium에서 활용)
Chrome Driver
Chrome 환경에서 네이버 DataLab에 접속하기 위한 드라이버입니다.
우선 자신의 크롬 버전을 확인할 필요가 있습니다. 하단의 이미지처럼 Chrome에 접속하였을 때, 우측 상단에 점 3개(?)를 클릭하게 되면 자신의 Chrome 설정을 확인할 수 있는 버튼이 있습니다.
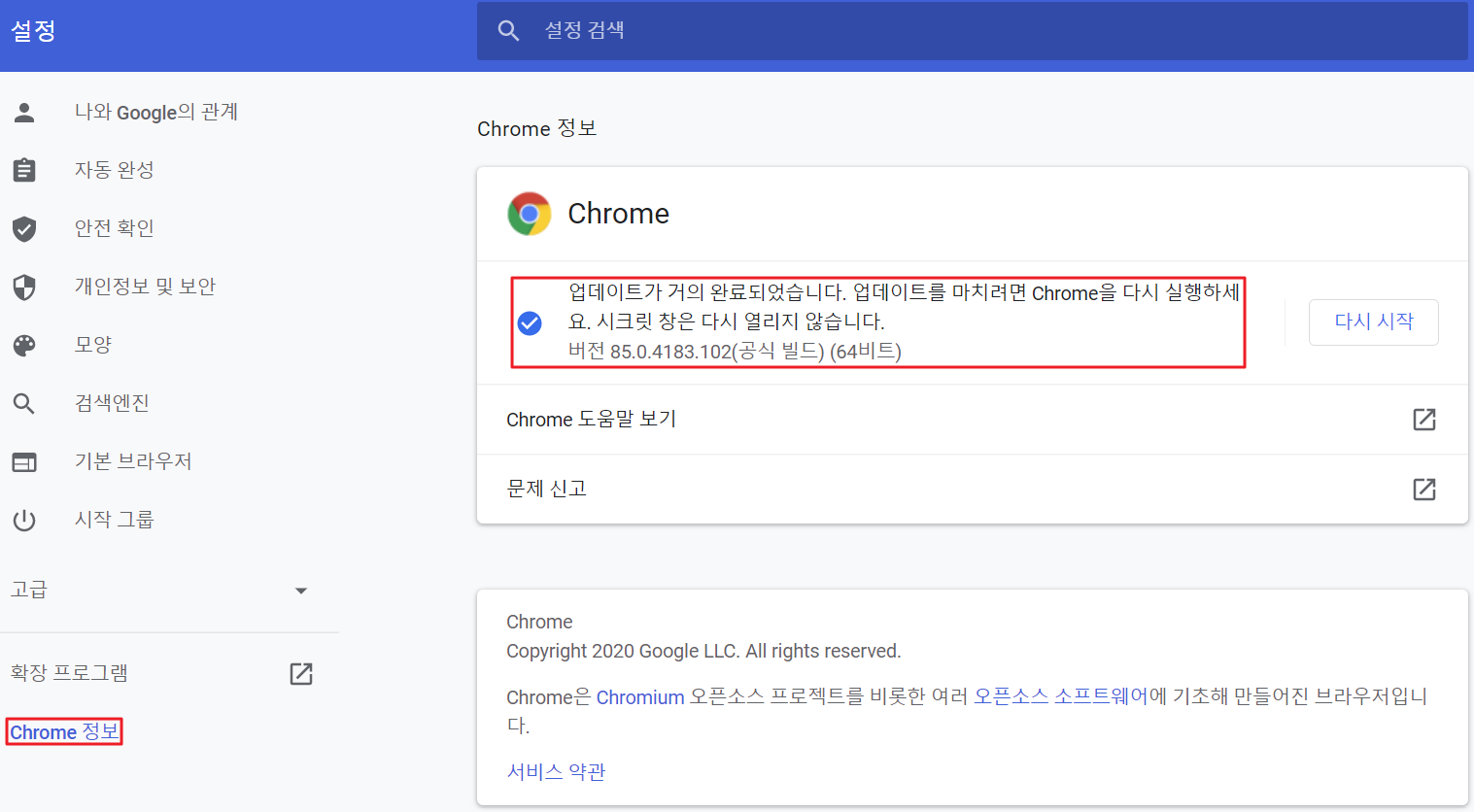
설정 버튼을 클릭하게 되면 자신의 설정 정보를 확인할 수 있는 창이 뜨게 되는데, 하단의 이미지처럼 왼쪽탭에서 Chrome 정보를 클릭하게 되면 현재 자신의 Chrome 버전을 확인할 수 있습니다.
버전을 확인하였으니 이제 Chrome 드라이버 사이트에 접속하여 자신의 버전에 적합한 드라이버를 다운로드해 보겠습니다. [Chrome 드라이버 다운로드 사이트 접속]
전 85버전이므로 해당 버전 다운로드 버튼을 클릭했습니다.
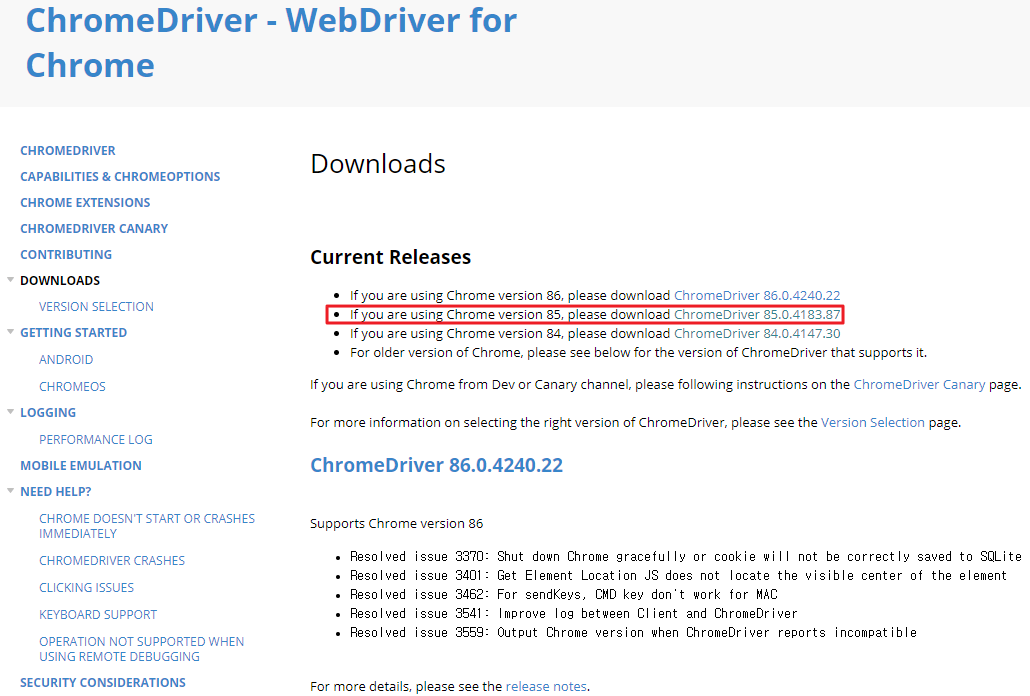
다운로드 버튼을 클릭하게 되면 OS 환경에 따른 압축파일들이 존재하는데, 그중 자신에게 적합한 파일을 클릭하여 다운로드하시면 됩니다. 전 Window를 사용하고 있으므로 win32.zip 파일을 다운로드했습니다.

다운로드한 파일을 압축 풀게되면 chromedriver.exe 파일이 있는 것을 확인하실 수 있을 텐데, 이 Chrome Driver 실행 파일을 네이버 급상승 검색어 크롤링 프로그램과 동일한 공간 및 폴더에 두시면 됩니다.

그럼 이제 네이버 급상승 검색어 프로그램에 관해서 살펴보겠습니다.
전체코드
from selenium import webdriver
from bs4 import BeautifulSoup as BS
import openpyxl
import os.path
import datetime as dt
naver_url = 'https://datalab.naver.com/keyword/realtimeList.naver?where=main'
output_path = 'D:/'
Today = dt.datetime.today().strftime('%Y_%m_%d')
order = 1
def get_datalab_keyword(naver_url):
Rank_Keyword=[]
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('headless')
driver = webdriver.Chrome('.\\chromedriver.exe',chrome_options = chrome_options)
driver.get(naver_url)
html = driver.page_source
soup = BS(html,'html.parser')
PlayTime = soup.findAll("span",{"class":"time_txt _title_hms"})
RankList = soup.findAll("span",{"class":"item_num"})
KeywordList = soup.findAll("span",{"class":"item_title"})
Rank_Keyword.append('수집시간 : ' + PlayTime[0].string)
for i in range(0,len(RankList)):
Rank_Keyword.append('[' + RankList[i].string + ']' + KeywordList[i].string)
driver.close()
return Rank_Keyword
def keyword_write_on_excel(Rank_Keyword):
global order
if(os.path.isfile(output_path + Today + '_naver_keyword.xlsx')):
keyword_wb = openpyxl.load_workbook(output_path + Today + '_naver_keyword.xlsx')
keyword_check = keyword_wb['Sheet']
while(True):
if(keyword_check.cell(1,order).value != None):
order+=1
else: break
keyword_ws = keyword_wb.active
keyword_ws.cell(1, order, Rank_Keyword[0])
for i in range(1, 21):
keyword_ws.cell(i + 1, order, Rank_Keyword[i])
keyword_wb.save(output_path + Today + '_naver_keyword.xlsx')
else:
keyword_wb = openpyxl.Workbook()
keyword_ws = keyword_wb.active
keyword_ws.cell(1,order,Rank_Keyword[0])
for i in range(1,21):
keyword_ws.cell(i + 1, order, Rank_Keyword[i])
keyword_wb.save(output_path + Today + '_naver_keyword.xlsx')
def excute_program():
keyword_write_on_excel(get_datalab_keyword(naver_url))
print("{} 기록완료".format(dt.datetime.today().strftime('%Y-%m-%d-%H-%M-%S')))
while (True):
p_today = dt.datetime.today()
while (True):
if (dt.datetime.today() - p_today >= dt.timedelta(seconds=1800)):
keyword_write_on_excel(get_datalab_keyword(naver_url))
print("{} 기록완료".format(dt.datetime.today().strftime('%Y-%m-%d-%H-%M-%S')))
break;
excute_program()
우선 필요한 라이브러리들을 살펴보도록 하겠습니다.
from selenium import webdriver
from bs4 import BeautifulSoup as BS
import openpyxl
import os.path
import datetime as dt
총 5개의 라이브러리를 import 하였고, 각 라이브러리들의 사용 용도는 코드를 살펴보면서 하나씩 알아보도록 하겠습니다.
naver_url = 'https://datalab.naver.com/keyword/realtimeList.naver?where=main' #1
output_path = 'D:/' #2
Today = dt.datetime.today().strftime('%Y_%m_%d') #3
order = 1 #4
#1 naver_url은 네이버의 DataLab에 접속하기 위한 url 주소입니다.
#2 크롤링한 급상승 검색어는 엑셀파일에 기록 및 저장하게 되는데, output_path는 해당 엑셀파일이 위치할 경로입니다. 전 D 드라이브를 파일이 저장될 경로로 지정했습니다.
#3 Today는 프로그램 실행 시점의 년/월/일을 표현하기 위한 변수입니다.
#4 order는 엑셀파일에 검색어를 저장할 때 사용할 column 값인데, 하단의 주요 코드들을 살펴보면 어렵지 않게 이해하실 수 있습니다.
이제 네이버의 DataLab에서 순위에 따른 급상승 검색어와 기준 시간을 크롤링하는 get_datalab_keyword 함수의 코드를 살펴보겠습니다.
def get_datalab_keyword(naver_url):
Rank_Keyword=[] #1
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('headless') #2
driver = webdriver.Chrome('.\\chromedriver.exe',chrome_options = chrome_options) #3
driver.get(naver_url) #4
html = driver.page_source
soup = BS(html,'html.parser') #5
PlayTime = soup.findAll("span",{"class":"time_txt _title_hms"}) #6
RankList = soup.findAll("span",{"class":"item_num"}) #7
KeywordList = soup.findAll("span",{"class":"item_title"}) #8
Rank_Keyword.append('수집시간 : ' + PlayTime[0].string) #9
for i in range(0,len(RankList)):
Rank_Keyword.append('[' + RankList[i].string + ']' + KeywordList[i].string) #10
driver.close() #11
return Rank_Keyword
#1 크롤링한 순위에 따른 급상승 검색어와 기준 시간을 저장하기 위한 리스트입니다.
#2 위에서 살펴본 chromedriver.exe의 실행 옵션을 지정해 주기 위함인데, Chrome 드라이버 사용 시 Chrome 창을 띄우지 않고 백그라운드에서 작업하기 위해 사용한 옵션입니다.
#3 사용할 chromedriver.exe의 경로와 사용할 옵션을 지정했습니다.
#4 chromedriver.exe를 활용하여 DataLab에 접속하는 코드입니다. 아무 옵션 없이 Chrome 드라이버를 활용하여 사이트에 접속하게 될 경우 Chrome 창이 함께 띄워지지만, #2에서 지정한 옵션으로 인해 Chrome 창이 열리지 않고 작업이 이뤄집니다.
다만, DataLab에 접속하게 되면 항상 하단의 이미지와 동일한 상세 옵션과 전체 연령 기준으로 접속하게 됩니다. 따라서 이번 크롤링 프로그램은 아래와 같이 정해진 옵션과 연령을 기준으로 급상승 검색어를 크롤링하게 되는 점 참고 부탁드립니다.
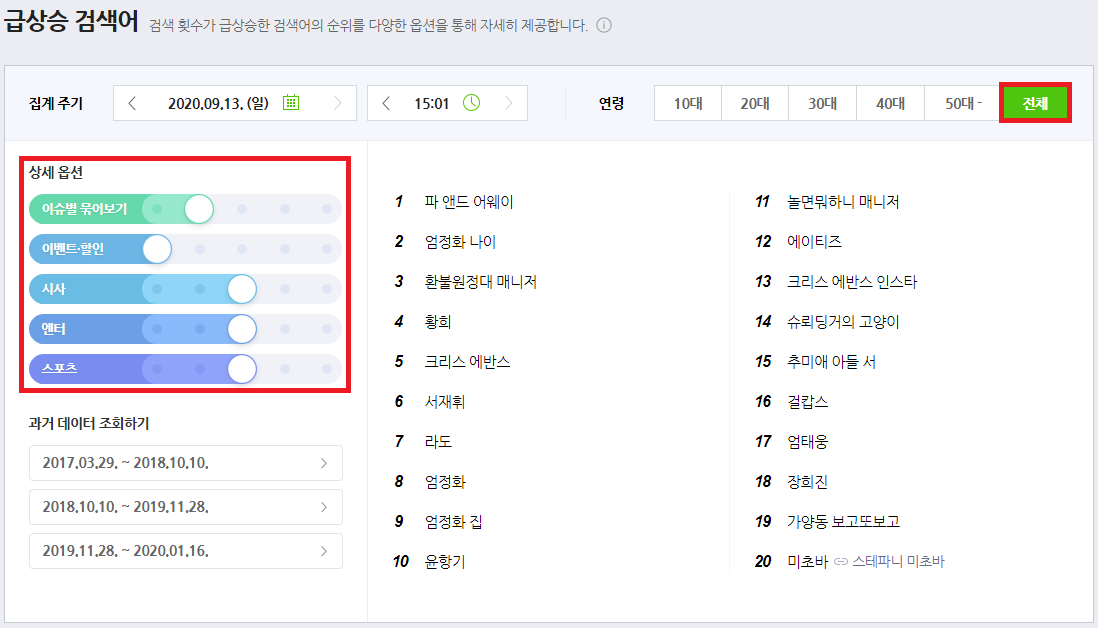
(추후에 상세 옵션과 연령대를 지정할 수 있는 기능을 넣을 예정입니다. 아마 V3에서…)
#5 DataLab으로의 접속 이후에 BeautifulSoup 라이브러리를 활용하여 html 코드 정보를 획득했습니다.
#6 html 코드에서 BeautifulSoup의 findAll 함수를 활용하여 급상승 검색어의 기준 시간 정보를 획득했습니다.
#7 html 코드에서 BeautifulSoup의 findAll 함수를 활용하여 급상승 검색어의 순위 정보를 획득했습니다.
#8 html 코드에서 BeautifulSoup의 findAll함수를 활용하여 급상승 검색어를 획득했습니다.
#9 & #10 검색 기준 시간과 순위 정보 및 검색어 정보를 Rank_Keyword 리스트에 저장했습니다.
#11 close 명령어를 활용하여 백그라운드에서 작업이 끝난 Chrome 창을 닫아줍니다.
다음으로 엑셀 파일에 검색어의 기준 시간과 순위에 따른 급상승 검색어들을 입력하는 keyword_write_on_excel 함수에 대해서 알아보겠습니다.
def keyword_write_on_excel(Rank_Keyword):
global order
if(os.path.isfile(output_path + Today + '_naver_keyword.xlsx')): #1
keyword_wb = openpyxl.load_workbook(output_path + Today + '_naver_keyword.xlsx')
keyword_check = keyword_wb['Sheet']
while(True):
if(keyword_check.cell(1,order).value != None): #2
order+=1
else: break
keyword_ws = keyword_wb.active
keyword_ws.cell(1, order, Rank_Keyword[0]) #3
for i in range(1, 21):
keyword_ws.cell(i + 1, order, Rank_Keyword[i]) #4
keyword_wb.save(output_path + Today + '_naver_keyword.xlsx')
else: #5
keyword_wb = openpyxl.Workbook()
keyword_ws = keyword_wb.active
keyword_ws.cell(1,order,Rank_Keyword[0])
for i in range(1,21):
keyword_ws.cell(i + 1, order, Rank_Keyword[i])
keyword_wb.save(output_path + Today + '_naver_keyword.xlsx')
#1 우선 지정해둔 output_path 경로에 프로그램을 실행하는 시점의 년/월/일을 기준으로 하는 엑셀 파일이 존재하는지 확인하는 코드입니다. 만약 당일 프로그램을 실행한 적이 있다면 엑셀 파일이 생성되어 있으므로, 해당 파일을 열고 추가적으로 검색어를 기록하는 작업을 수행하게 됩니다.
#2 급상승 검색어 정보가 저장되어 있는 파일을 확인했을 때, 첫 번째 행에서 값이 비어 있는 열을 찾는 코드입니다. 만약 하단의 이미지처럼 엑셀 파일의 1행 B열까지 데이터가 있다면, 1행 C열부터 새롭게 검색어 정보를 입력하게 되는 원리입니다.
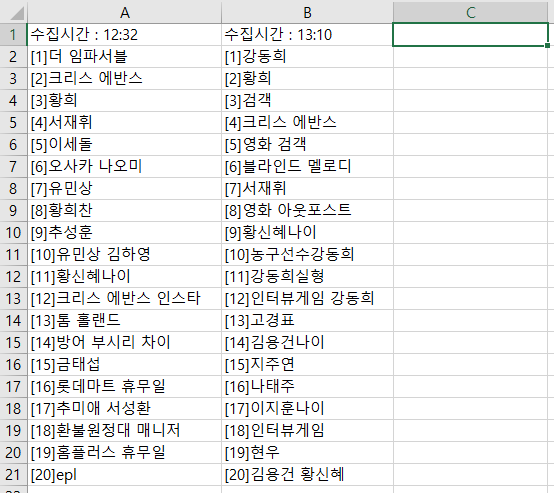
#3 비어 있는 열을 찾았다면 먼저 Rank_Keyword 리스트의 첫 번째 데이터인 급상승 검색어의 기준 시간 정보를 입력하게 됩니다.
#4 검색어의 기준 시간 정보 입력 이후에 1위부터 20위까지의 급상승 검색어를 입력하게 됩니다.
#5 만약 특정일에 프로그램을 실행한 적이 없다면 #1에서 급상승 검색어가 저장되어 있는 엑셀파일을 찾지 못하게 됩니다. 이때 새롭게 당일의 년/월/일 정보가 포함되어 있는 이름의 엑셀파일을 생성하고 저장하게 되는데, 처음 기록하는 파일이므로 1행 A열부터 급상승 검색어 정보가 입력될 것입니다.
마지막으로 일정 시간마다 전체적인 과정을 실행하는 excute_program 함수에 대해서 알아보겠습니다.
def excute_program():
keyword_write_on_excel(get_datalab_keyword(naver_url)) #1
print("{} 기록완료".format(dt.datetime.today().strftime('%Y-%m-%d-%H-%M-%S'))) #2
while (True):
p_today = dt.datetime.today() #3
while (True):
if (dt.datetime.today() - p_today >= dt.timedelta(seconds=1800)): #4
keyword_write_on_excel(get_datalab_keyword(naver_url))
print("{} 기록완료".format(dt.datetime.today().strftime('%Y-%m-%d-%H-%M-%S')))
break;
#1 프로그램이 실행되면 우선 get_datalab_keyword 함수를 활용하여 얻은 급상승 검색어 정보를 keyword_write_on_excel 함수로 전달하여 엑셀 파일을 생성 및 저장하게 됩니다.
#2 성공적으로 #1의 과정이 실행된다면 datetime.today 함수를 활용해 얻은 시간 정보와 함께 기록 완료라는 문자를 출력합니다.
#3 다음 실행까지의 시간을 계산하기 위해 지속적으로 시간을 확인하면서 기록해 둔 p_today 시간 값과 비교하여 차이가 1800초 이상일 때 30분이 경과했다고 여기고, #1의 과정을 다시 수행하게 됩니다. 수행 주기를 바꾸고 싶다면 원하는 주기의 시간 값을 초 단위로 계산해서 seconds에 입력하면 됩니다.
정리하자면 chromedriver.exe와 같은 경로에서 급상승 검색어 크롤링 코드나 프로그램을 실행하게 되면 앞서 설명한 함수들이 작동하며 검색어들이 시간대별로 분류되어 엑셀 파일에 저장될 것입니다.
전체적인 코드와 실행 프로그램 한 번 더 첨부하겠습니다.
from selenium import webdriver
from bs4 import BeautifulSoup as BS
import openpyxl
import os.path
import datetime as dt
naver_url = 'https://datalab.naver.com/keyword/realtimeList.naver?where=main'
output_path = 'D:/'
Today = dt.datetime.today().strftime('%Y_%m_%d')
order = 1
def get_datalab_keyword(naver_url):
Rank_Keyword=[]
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('headless')
driver = webdriver.Chrome('.\\chromedriver.exe',chrome_options = chrome_options)
driver.get(naver_url)
html = driver.page_source
soup = BS(html,'html.parser')
PlayTime = soup.findAll("span",{"class":"time_txt _title_hms"})
RankList = soup.findAll("span",{"class":"item_num"})
KeywordList = soup.findAll("span",{"class":"item_title"})
Rank_Keyword.append('수집시간 : ' + PlayTime[0].string)
for i in range(0,len(RankList)):
Rank_Keyword.append('[' + RankList[i].string + ']' + KeywordList[i].string)
driver.close()
return Rank_Keyword
def keyword_write_on_excel(Rank_Keyword):
global order
if(os.path.isfile(output_path + Today + '_naver_keyword.xlsx')):
keyword_wb = openpyxl.load_workbook(output_path + Today + '_naver_keyword.xlsx')
keyword_check = keyword_wb['Sheet']
while(True):
if(keyword_check.cell(1,order).value != None):
order+=1
else: break
keyword_ws = keyword_wb.active
keyword_ws.cell(1, order, Rank_Keyword[0])
for i in range(1, 21):
keyword_ws.cell(i + 1, order, Rank_Keyword[i])
keyword_wb.save(output_path + Today + '_naver_keyword.xlsx')
else:
keyword_wb = openpyxl.Workbook()
keyword_ws = keyword_wb.active
keyword_ws.cell(1,order,Rank_Keyword[0])
for i in range(1,21):
keyword_ws.cell(i + 1, order, Rank_Keyword[i])
keyword_wb.save(output_path + Today + '_naver_keyword.xlsx')
def excute_program():
keyword_write_on_excel(get_datalab_keyword(naver_url))
print("{} 기록완료".format(dt.datetime.today().strftime('%Y-%m-%d-%H-%M-%S')))
while (True):
p_today = dt.datetime.today()
while (True):
if (dt.datetime.today() - p_today >= dt.timedelta(seconds=1800)):
keyword_write_on_excel(get_datalab_keyword(naver_url))
print("{} 기록완료".format(dt.datetime.today().strftime('%Y-%m-%d-%H-%M-%S')))
break;
excute_program()
네이버 급상승 검색어 크롤링 프로그램 : Naver_Keyword_Crawling_DataLab.exe

앞서 설명드린 대로 네이버 급상승 검색어 크롤링 코드 및 프로그램을 chromedriver.exe와 같은 경로에 두고 실행하게 되면 D 드라이브에 상단의 이미지처럼 당일 날짜가 포함된 이름의 엑셀 파일이 생성될 것입니다.

생성된 엑셀 파일을 확인해 보면 검색어 수집시간과 함께 1위부터 20위까지의 네이버 급상승 검색어가 기록되어 있는 것을 확인할 수 있습니다.
참고로 파이썬 코드를 exe 파일 형식의 실행 파일로 만들고 싶다면, 커맨드창에서 해당 파이썬 코드 파일이 있는 경로로 이동하여 pyinstaller -F -n 실행파일이름.exe 코드파일이름.py 명령을 수행하면 됩니다. pyinstaller 라이브러리를 활용한 방법인데, 해당 라이브러리가 없다면 설치가 필요합니다.
그럼 네이버 급상승 검색어 크롤링 및 엑셀 파일에 기록하기(V2) 설명을 마치도록 하겠습니다.
다음 포스팅에는 상세옵션과 연령대 설정이 가능한 프로그램을 소개해 드리겠습니다.(V3)