
마케터의 네이버 급상승 검색어 크롤링 해보기
Naver 급상승 검색어 크롤링
Python의 BeautifulSoup를 활용하여 네이버 메인의 급상승 검색어를 크롤링하는 프로그램을 만들었지만, 네이버의 html 코드가 수정되고, BeautifulSoup만으로는 모든 데이터를 가져오지 못하게 되어 새로운 프로그램을 만들었습니다. 관련하여 내용을 원하신다면 네이버 급상승 검색어 크롤링(V2) 포스트로 확인해 주세요.
우선 전체적인 코드와 실행 프로그램을 첨부하겠다. GD_Naver_Crawling.exe는 30분마다 네이버 메인의 1위부터 20위까지의 급상승 검색어를 크롤링해서 D 드라이브에 엑셀 파일로 저장하는 프로그램이다. 코드에 관한 설명도 하단에 적었으니 읽어보길 바란다.
실행 프로그램: GD_Naver_Crawling.exe
전체코드
import urllib.request as ur
from bs4 import BeautifulSoup as BS
import re
import openpyxl
import os.path
import datetime as dt
naver_url = "https://www.naver.com/"
Today = dt.datetime.today().strftime('%Y-%m-%d')
order=1
def GD_naver_pick_url(url):
GD_naver_rank_words=[]
GD_html_source = ur.urlopen(url)
GD_soup = BS(GD_html_source, 'html.parser')
GD_words = GD_soup.findAll('span', attrs={'class': 'ah_k'})
GD_time = GD_soup.find('p', attrs={'class': 'ah_time'})
GD_time = re.sub(' 기준 도움말', '', GD_time.text)
GD_naver_rank_words.append(GD_time)
for i in range(20):
GD_naver_rank_words.append(GD_words[i].text)
return GD_naver_rank_words
def GD_write_on_excel(list):
global order
if(os.path.isfile('D:/'+Today+'_naver_search.xlsx')):
GD_wb = openpyxl.load_workbook('D:/'+Today+'_naver_search.xlsx')
GD_check = GD_wb['Sheet']
while(True):
if(GD_check.cell(1,order).value != None):
order+=1
else: break
GD_ws = GD_wb.active
GD_ws.cell(1, order, list[0])
for i in range(1, 21):
GD_ws.cell(i + 1, order, '{}위 : {}'.format(i,list[i]))
GD_wb.save('D:/'+Today+'_naver_search.xlsx')
else:
GD_wb = openpyxl.Workbook()
GD_ws = GD_wb.active
GD_ws.cell(1,order,list[0])
for i in range(1,21):
GD_ws.cell(i+1, order, '{}위 : {}'.format(i,list[i]))
GD_wb.save('D:/'+Today+'_naver_search.xlsx')
def GD_excute_program():
GD_write_on_excel(GD_naver_pick_url(naver_url))
print("{} 기록완료".format(dt.datetime.today().strftime('%Y-%m-%d-%H-%M-%S')))
while (True):
p_today = dt.datetime.today()
while (True):
if (dt.datetime.today() - p_today >= dt.timedelta(seconds=1800)):
GD_write_on_excel(GD_naver_pick_url(naver_url))
print("{} 기록완료".format(dt.datetime.today().strftime('%Y-%m-%d-%H-%M-%S')))
break;
GD_excute_program()
이제 파이썬을 활용해서 네이버의 급상승 검색어를 크롤링하고 액셀 파일에 저장하는 프로그램을 만드는 과정을 알아보자.
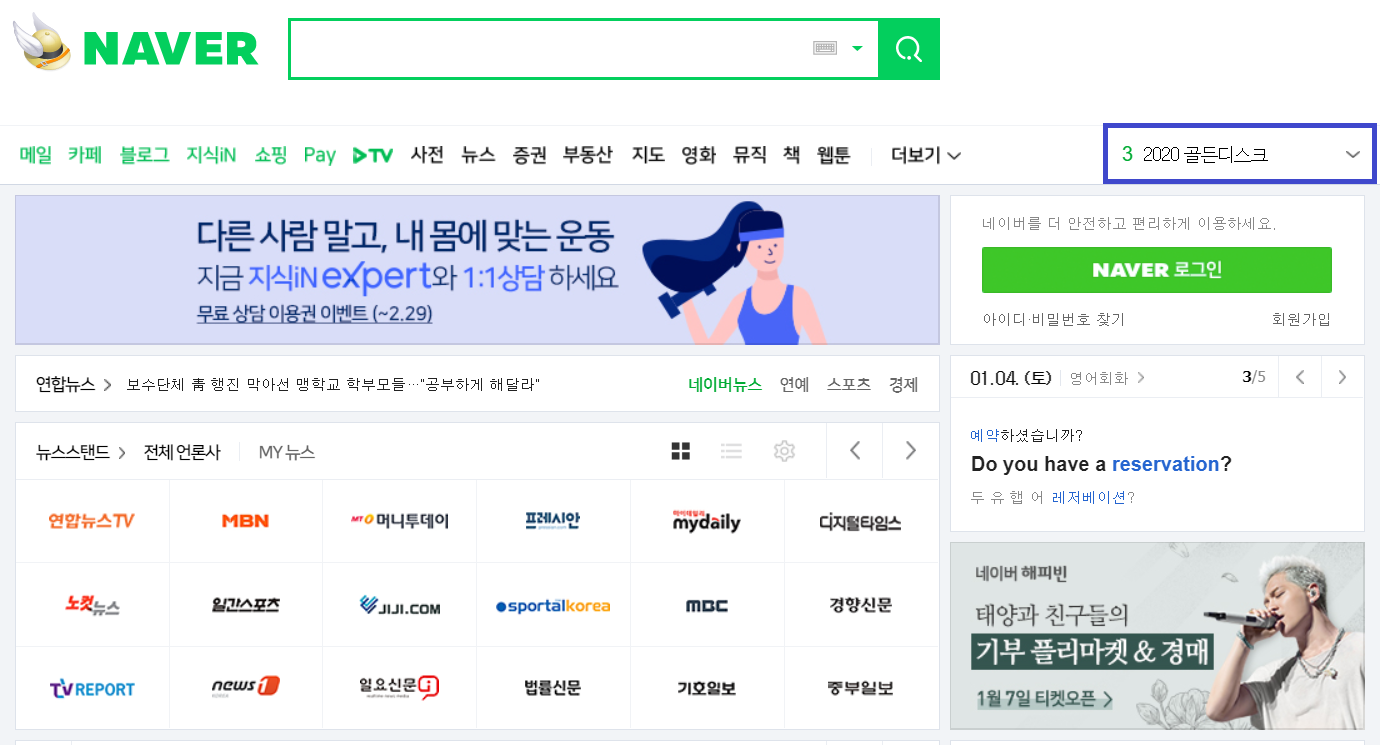
네이버 메인 페이지의 일부분이다. 파란색 네모칸은 1위부터 20위까지의 급상승 검색어를 실시간으로 보여주는 배너이다. 바로 이 배너에 보이는 1위부터 20위까지의 검색어들을 크롤링 해 볼 것이다.
우선 필요한 라이브러리들을 살펴보도록 하자.
import urllib.request as ur
from bs4 import BeautifulSoup as BS
import re
import openpyxl
import os.path
import datetime as dt
6개의 라이브러리를 import 했다. 각 라이브러리들의 사용 용도는 코드를 살펴보면서 하나씩 알아보도록 하자.
naver_url = "https://www.naver.com/" #1
Today = dt.datetime.today().strftime('%Y-%m-%d') #2
order=1 #3
#1 naver_url은 Naver 사이트 접속에 필요한 url 값이다.
#2 Today는 datetime.datetime.today 함수를 활용하여 구한 시간 정보를 strftime 함수를 활용하여 ‘연도-월-일’ 값의 형태로 포맷 후에 부여한 값이다. 다시 말하자면, 프로그램을 실행하는 시점의 날짜를 연도와 월 그리고 일수로 표현한 것인데, 예를 들어 2020년 1월 4일에 프로그램을 실행한다면 Today에는 ‘2020-01-04’ 값이 부여될 것이다.
#3 order는 크롤링한 검색어들과 기준 시간을 저장할 엑셀파일의 cell 값 위치를 지정하기 위해서 사용되는 변수다. 앞으로의 코드를 살펴보면서 추가적인 설명을 하겠다.
def GD_naver_pick_url(url):
GD_naver_rank_words=[] #1
GD_html_source = ur.urlopen(url) #2
GD_soup = BS(GD_html_source, 'html.parser') #3
GD_words = GD_soup.findAll('span', attrs={'class': 'ah_k'}) #4
GD_time = GD_soup.find('p', attrs={'class': 'ah_time'}) #5
GD_time = re.sub(' 기준 도움말', '', GD_time.text) #6
GD_naver_rank_words.append(GD_time) #7
for i in range(20):
GD_naver_rank_words.append(GD_words[i].text) #8
return GD_naver_rank_words #9
이제 Naver 메인 페이지에서 급상승 검색어와 검색 시간을 크롤링하는 GD_naver_pick_url 함수의 코드를 살펴보자.
#1 GD_naver_rank_words는 크롤링한 시간 정보와 20개의 급상승 검색어가 저장될 리스트이다.
#2 GD_html_source에는 urllib.request.urlopen 함수를 활용하여 얻은 Naver 메인 페이지의 웹 정보가 저장된다.
#3 GD_html_source에 저장되어 있는 웹 정보는 BeautifulSoup 함수를 활용한 html 정보 추출에 사용된다. 추출한 html 정보는 GD_soup에 저장된다.
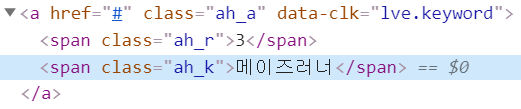
#4 span 태그이면서 ‘ah_k’ 클래스를 가진 태그 내에 급상승 검색어 정보가 있는 것을 확인할 수 있다. findAll 함수를 활용하여 GD_soup에 저장되어 있는 관련 태그 정보들을 추출하고, GD_words에 저장한다.
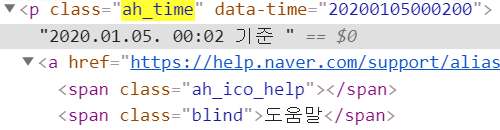
#5 p 태그이면서 ‘ah_time’ 클래스를 가진 태그 내에 검색 시간 정보가 있는 것을 확인할 수 있다. find 함수를 활용하여 GD_soup에 저장되어 있는 관련 태그 정보를 추출하고, GD_time에 저장한다.
#6 GD_time에 저장되어 있는 태그 정보에서 text를 추출해 보고 사용하지 않는 불필요한 정보는 삭제해 주도록 한다. re.sub 함수를 활용하여 text 정보에서 ‘ 기준 도움말’ 문자열을 삭제해 주도록 한다.
#7 GD_naver_rank_words 리스트에 정제한 검색 시간 정보를 넣어준다.
#8 GD_naver_rank_words 리스트에 급상승 검색어 정보들을 넣어준다. for 문을 사용하여 정확히 20개의 급상승 검색어 정보를 넣는 이유는 Naver 메인 페이지에는 급상승 검색어 관련 태그가 40개이기 때문이다. Naver 메인 페이지의 급상승 검색어 구간의 움직이면서 보여지는 1위부터 20위까지의 검색어들과 마우스 커서를 올렸을 때 보이는 1위부터 20위까지의 검색어들을 표현하기 위해 총 40개의 태그가 존재한다. 다시 말하자면, #4과정에서 1위부터 20위까지의 급상승 검색어 관련 태그 이후 동일하게 1위부터 20위까지의 급상승 검색어 관련 태그가 순서대로 추출되어 진다. 따라서 중복된 값은 필요 없으므로, 첫 1위부터 20위까지의 급상승 검색어 정보를 가지고 있는 20개의 태그에서 text 정보를 GD_naver_rank_words에 저장한다.
#9 검색 시간정보와 급상승 검색어 20개가 저장되어 있는 GD_naver_rank_words를 반환한다.
def GD_write_on_excel(list):
global order #1
if(os.path.isfile('D:/'+Today+'_naver_search.xlsx')): #2
GD_wb = openpyxl.load_workbook('D:/'+Today+'_naver_search.xlsx') #3
GD_check = GD_wb['Sheet'] #4
while(True):
if(GD_check.cell(1,order).value != None): #5
order+=1
else: break
GD_ws = GD_wb.active #6
GD_ws.cell(1, order, list[0]) #7
for i in range(1, 21): #8
GD_ws.cell(i + 1, order, '{}위 : {}'.format(i,list[i]))
GD_wb.save('D:/'+Today+'_naver_search.xlsx') #9
else:
GD_wb = openpyxl.Workbook() #10
GD_ws = GD_wb.active
GD_ws.cell(1,order,list[0])
for i in range(1,21):
GD_ws.cell(i+1, order, '{}위 : {}'.format(i,list[i]))
GD_wb.save('D:/'+Today+'_naver_search.xlsx')
다음으로 엑셀 파일에 검색 시간과 급상승 검색어들을 입력하는 GD_write_on_excel 함수에 대해서 알아보자.
#1 검색 시간과 급상승 검색어들이 저장될 엑셀 파일의 열을 선택하는 기준이 되는 변수이다.
#2 지정해 둔 D 드라이브에 프로그램을 실행하는 날짜 값이 담긴 Today와 ‘_naver_search’가 합쳐진 이름의 엑셀 파일이 있는지 확인한다.
#3 엑셀 파일이 존재한다면 해당 엑셀 파일을 openpyxl.load_workbook 함수를 활용하여 파이썬 환경에서 작업할 수 있도록 한다.
#4 엑셀 파일에서 작업을 진행할 시트를 선택한다.
#5 엑셀 파일에 정보를 입력할 때, 검색 시간을 입력하고 그 다음 행에 이어서 급상승 검색어들을 입력할 것이다. 그리고 다음 시간대의 정보들은 열을 바꿔서 다음 열에 입력을 할 것이다. 따라서 정보를 입력하기 전에 해당 열의 첫 번째 행에 정보가 입력되어 있는지 확인하는 절차가 필요하다. GD_check.cell(1,order).value를 활용해서 1행 order열에 값의 여부를 확인하고 None 값의 출력 여부로 order 값에 1을 더해 다음 열을 검사하는 방식을 사용했다.
#6 엑셀 파일에 정보를 입력하기 위해 GD_wb.active로 활성화시켰다.
#7 cell 함수를 활용하여 order열의 1행에는 리스트의 첫 번째 요소인 검색 시간 정보를 입력한다.
#8 2행부터 급상승 검색어 정보들을 순차적으로 입력할 것이다. 마찬가지로 cell 함수를 활용하여 1위부터 20위까지의 급상승 검색어 정보들을 입력했다.
#9 검색 시간과 급상승 검색어의 입력이 끝난다면, D 드라이브에 엑셀 파일을 저장한다.
#10 엑셀 파일이 D 드라이브에 없을 때는 새롭게 엑셀 파일을 만들어줘야 한다. openpyxl.Workbook 함수를 활용하여 새로운 엑셀 파일 환경을 만들었다.
def GD_excute_program():
GD_write_on_excel(GD_naver_pick_url(naver_url)) #1
print("{} 기록완료".format(dt.datetime.today().strftime('%Y-%m-%d-%H-%M-%S'))) #2
while (True):
p_today = dt.datetime.today() #3
while (True):
if (dt.datetime.today() - p_today >= dt.timedelta(seconds=1800)): #4
GD_write_on_excel(GD_naver_pick_url(naver_url))
print("{} 기록완료".format(dt.datetime.today().strftime('%Y-%m-%d-%H-%M-%S')))
break;
마지막으로 일정 시간마다 전체적인 과정을 실행하는 GD_excute_program 함수에 대해서 알아보자.
#1 프로그램이 실행되면 우선 크롤링 및 엑셀에 정보 입력을 1회 실행한다. 만들어 둔 GD_naver_pick_url 함수와 GD_write_on_excel 함수를 활용하여 수행한다.
#2 성공적으로 #1의 과정이 실행된다면 datetime.today 함수를 활용해 얻은 시간과 함께 기록 완료라는 문자열을 출력한다.
#3 다음 실행까지의 시간을 계산하기 위해 현재 시간을 기록한다.
#4 지속적으로 시간을 확인하면서 기록해 둔 p_today 시간 값과 비교하여 timedelta 함수를 이용한 차이가 1800초 이상일 때 30분이 경과했다고 여기고, 크롤링 및 정보 입력 과정을 다시 수행한다. 수행 주기를 바꾸고 싶다면 원하는 주기의 시간 값을 초 단위로 계산해서 seconds에 대입하면 된다.
프로그램에 필요한 함수들을 전부 살펴봤다. 결국 네이버의 검색 시간 기준 급상승 검색어를 크롤링하고, 엑셀에 입력하는 과정을 수행하기 위해서는 GD_excute_program 함수만 실행시켜 주면 된다.
전체적인 코드와 실행 프로그램을 한 번 더 첨부한다.
import urllib.request as ur
from bs4 import BeautifulSoup as BS
import re
import openpyxl
import os.path
import datetime as dt
naver_url = "https://www.naver.com/"
Today = dt.datetime.today().strftime('%Y-%m-%d')
order=1
def GD_naver_pick_url(url):
GD_naver_rank_words=[]
GD_html_source = ur.urlopen(url)
GD_soup = BS(GD_html_source, 'html.parser')
GD_words = GD_soup.findAll('span', attrs={'class': 'ah_k'})
GD_time = GD_soup.find('p', attrs={'class': 'ah_time'})
GD_time = re.sub(' 기준 도움말', '', GD_time.text)
GD_naver_rank_words.append(GD_time)
for i in range(20):
GD_naver_rank_words.append(GD_words[i].text)
return GD_naver_rank_words
def GD_write_on_excel(list):
global order
if(os.path.isfile('D:/'+Today+'_naver_search.xlsx')):
GD_wb = openpyxl.load_workbook('D:/'+Today+'_naver_search.xlsx')
GD_check = GD_wb['Sheet']
while(True):
if(GD_check.cell(1,order).value != None):
order+=1
else: break
GD_ws = GD_wb.active
GD_ws.cell(1, order, list[0])
for i in range(1, 21):
GD_ws.cell(i + 1, order, '{}위 : {}'.format(i,list[i]))
GD_wb.save('D:/'+Today+'_naver_search.xlsx')
else:
GD_wb = openpyxl.Workbook()
GD_ws = GD_wb.active
GD_ws.cell(1,order,list[0])
for i in range(1,21):
GD_ws.cell(i+1, order, '{}위 : {}'.format(i,list[i]))
GD_wb.save('D:/'+Today+'_naver_search.xlsx')
def GD_excute_program():
GD_write_on_excel(GD_naver_pick_url(naver_url))
print("{} 기록완료".format(dt.datetime.today().strftime('%Y-%m-%d-%H-%M-%S')))
while (True):
p_today = dt.datetime.today()
while (True):
if (dt.datetime.today() - p_today >= dt.timedelta(seconds=1800)):
GD_write_on_excel(GD_naver_pick_url(naver_url))
print("{} 기록완료".format(dt.datetime.today().strftime('%Y-%m-%d-%H-%M-%S')))
break;
GD_excute_program()
실행 프로그램: GD_Naver_Crawling.exe
참고로 파이썬 코드를 exe 파일 형식의 실행 파일로 만들고 싶다면, 커맨드창에서 해당 파이썬 코드 파일이 있는 경로로 이동하여 pyinstaller -F -n 실행파일이름.exe 코드파일이름.py 명령을 수행하면 된다. pyinstaller 라이브러리를 활용한 방법인데, 해당 라이브러리가 없다면 설치가 필요하다.

코드 및 프로그램을 실행하게 되면 D 드라이브에 상단의 그림처럼 파일이 생성될 것이다.
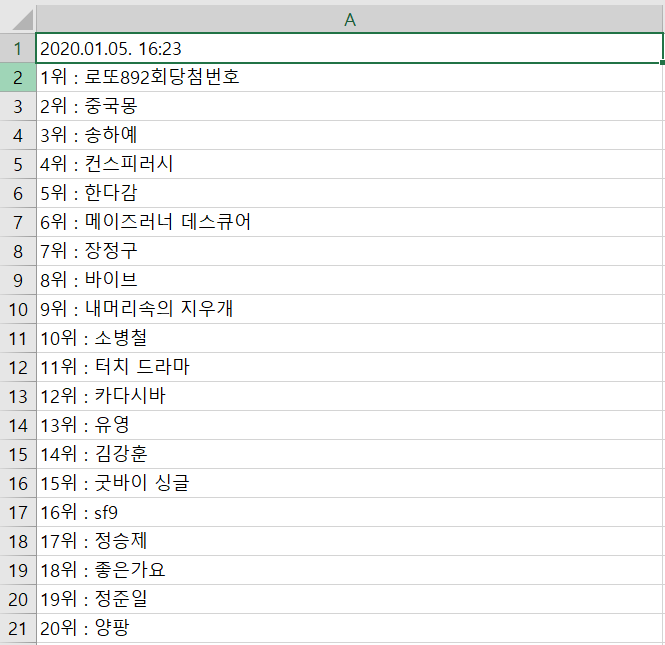
생성된 엑셀 파일을 확인해 보면 시간 정보와 함께 1위부터 20위까지의 급상승 검색어가 기록되어 있는 것을 확인할 수 있다.
네이버 급상승 검색어 크롤링 및 엑셀 파일에 기록하기 설명을 마치도록 하겠다.